How to Benchmark (Python) Code
While preparing to write the Writing Faster Python series, the first problem I faced was "How do I benchmark a piece of code in an objective yet uncomplicated way".
I could run python -m timeit <piece of code>, which is probably the simplest way of measuring how long it takes to execute some code[1]. But maybe it's too simple, and I owe my readers some way of benchmarking that won't be interfered by sudden CPU spikes on my computer?
So here are a couple of different tools and techniques I tried. At the end of the article, I will tell you which one I chose and why. Plus, I will give you some rules of thumb for when each tool might be handy.
python -m timeit
The easiest way to measure how long it takes to run some code is to use the timeit module. You can write python -m timeit your_code(), and Python will print out how long it took to run whatever your_code() does. I like to put the code I want to benchmark inside a function for more clarity, but you don't have to do this. You can directly write multiple Python statements separated by semicolons, and that will work just fine. For example, to see how long it takes to sum up the first 1,000,000 numbers, we can run this code:
python -m timeit "sum(range(1_000_001))"
20 loops, best of 5: 11.5 msec per loopHowever, python -m timeit approach has a major drawback - it doesn't separate the setup code from the code you want to benchmark. Let's say you have an import statement that takes a relatively long time to import compared to executing a function from that module. One such import can be import numpy. If we benchmark those two lines of code:
import numpy
numpy.arange(10)the import will take most of the time during the benchmark. But you probably don't want to benchmark how long it takes to import modules. You want to see how long it takes to execute some functions from that module.
python -m timeit -s "setup code"
To separate the setup code from the benchmarks, timeit supports -s parameter. Whatever code you pass here will be executed but won't be part of the benchmarks. So we can improve the above code and run it like this: python -m timeit -s "import numpy" "numpy.arange(10)".
python -m timeit -s "setup code" -n 10000
We can be a bit more strict and decide to execute our code the same number of times each time. By default, if you don't specify the '-n' (or --number) parameter, timeit will try to run your code 1, 2, 5, 10, 20, ... until the total execution time exceeds 0.2 seconds. A slow function will be executed once, but a very fast one will run thousands of times. If you think executing different code snippets a different number of times affects your benchmarks, you can set this parameter to a predefined number.
docker
One of the issues with running benchmarks with python -m timeit is that sometimes other processes on your computer might affect the Python process and randomly slow it down. For example, I've noticed that if I run my benchmarks with all the usual applications open (multiple Chrome instances with plenty of tabs, Teams and other messenger apps, etc.), they all take a bit longer than when I close basically all the apps on my computer.
So while trying to figure out how to avoid this situation, I decided to try to run my benchmarks in Docker. I came up with the following solution:
docker run -w /home -it -v $(pwd):/home python:3.10.4-alpine python -m timeit -s "<some setup code>" "my_function()"
The above code will:
- Run Python alpine Docker container (a small, barebones image with Python).
- Mount the current folder inside the Docker container (so we can access the files we want to benchmark).
- Run the same timeit command as before.
And the results seemed more consistent than without using Docker. Rerunning benchmarks multiple times, I was getting results with smaller deviations. I still had a deviation - some runs were slightly slower, and some were slightly faster. However, that was the case for short code examples (running under 1 second). For longer code examples (running at least a few seconds), the difference between runs was even around 5% (I've tested docker with my bubble sort example from Upgrade Your Python Version article). So, as one vigilant commenter suggested, Docker doesn't really help much here.
Python benchmarking libraries
At some point, you might decide that getting a "best of 5" number that timeit returns by default is not enough. What if I need to know what's the most pessimistic scenario (the maximum time it took to run my code)? Or what's the difference between the slowest and fastest run? Is this difference huge, and my function runs in a completely unpredictable amount of time? Or is it so tiny that it's almost negligible?
There are better benchmarking tools that offer more statistics about your code.
rich-bench
The first tool I checked was the rich-bench package that was created by Anthony Shaw together with his anti-patterns repository for a PyCon talk. This small tool can benchmark a set of files with different code examples and present the results in a nicely formatted table. Each benchmark will compare two different functions and present the mean, min, and max of the results, so you can easily see the spread between the results.
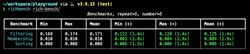
pyperf
If you need a more advanced benchmarking tool, you probably can't go wrong if you choose the official tool used by the Python Performance Benchmark Suite - an authoritative source of benchmarks for all Python implementations. pyperf is an exhaustive tool with many different features, including automatic calibration, detection of unstable results, tracking memory usage, and different modes of work, depending if you want to compare different pieces of code or get a bunch of stats for one function.
Let's see an example. For the benchmarks, I will use a simple but inefficient function to calculate a sum of powers of the first 1,000,000 numbers:
sum(n * n for n in range(1_000_001)).
Here is the output from timeit module:
$ python -m timeit "sum(n * n for n in range(1_000_001))"
5 loops, best of 5: 41 msec per loopAnd here is the output of the pyperf:
$ python -m pyperf timeit "sum(n * n for n in range(1_000_001))" -o bench.json
.....................
Mean +- std dev: 41.5 ms +- 1.1 msThe results are very similar, but with the -o parameter, we told pyperf to store the benchmark results in a JSON file, so now we can analyze them and get much more information:
$ python -m pyperf stats bench.json
Total duration: 14.5 sec
Start date: 2022-11-09 18:19:37
End date: 2022-11-09 18:19:53
Raw value minimum: 163 ms
Raw value maximum: 198 ms
Number of calibration run: 1
Number of run with values: 20
Total number of run: 21
Number of warmup per run: 1
Number of value per run: 3
Loop iterations per value: 4
Total number of values: 60
Minimum: 40.8 ms
Median +- MAD: 41.3 ms +- 0.2 ms
Mean +- std dev: 41.5 ms +- 1.1 ms
Maximum: 49.6 ms
0th percentile: 40.8 ms (-2% of the mean) -- minimum
5th percentile: 40.9 ms (-1% of the mean)
25th percentile: 41.2 ms (-1% of the mean) -- Q1
50th percentile: 41.3 ms (-0% of the mean) -- median
75th percentile: 41.5 ms (+0% of the mean) -- Q3
95th percentile: 41.9 ms (+1% of the mean)
100th percentile: 49.6 ms (+20% of the mean) -- maximum
Number of outlier (out of 40.7 ms..41.9 ms): 3hyperfine
And in case you want to benchmark some code that is not Python code, there is always the hyperfine that can be used to benchmark any CLI command. hyperfine has a similar set of features as the pyperf does. It automatically does warmup runs, clears the cache, and detect statistical outliers. And all that, with nice progress bars and colors, just makes the output looks beautiful.
You can run it for one command, and it will return the usual information like the mean, min, and max time, standard deviation, number of runs, etc. But you can also pass multiple commands, and you will get a comparison of which one was faster:
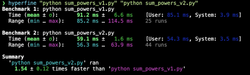
timeit is just fine...for me
In the end, I chose a very simple way of benchmarking: python -m timeit -s "setup code" "code to benchmark". I don't have to use the perfect benchmarking method (if it even exists). . That would be necessary if I were to benchmark one piece of code and share the results with the world. I couldn't use a random, inefficient method of measuring and tell you "this piece of code is bad because it runs in 15 seconds". You could use a better benchmarking tool, run it on a powerful computer and end up with the same code running in 1.5 seconds.
Comparing two pieces of code is a different story. Sure, a good, reliable benchmarking methodology is important. But in the end, we care about the relative speed difference between the code examples. If my computer runs "Example A" in 10 seconds and "Example B" in 20 seconds, but your computer runs them in 5 and 10 seconds respectively, we can both conclude that "Example B" is twice as slow.
Using timeit is good enough. It lets me separate the setup code from the actual code I want to benchmark. And if you want to run the same benchmarks on your computer, you can do this right away. You already have timeit installed with your distribution of Python. You don't have to install any additional library or set up Docker.
Much more important thing than the most accurate tool is how you set up your benchmarks.
Beware of how you structure your code
Running benchmarks is the easy part. The tricky part is to remember to write your code in a way that won't "cheat". When I first wrote Sorting Lists article, I was so happy to find that sort() was so much faster than sorted(). "OMG, I found the holy grail of sorting in Python" - I thought. Then someone pointed out that list.sort() sorts the list in place. So if I run my benchmarks, the first iteration will sort the list (which is slow), and each next iteration will sort an already sorted list (which is much faster). I had to update my article and start paying more attention to how I organize my benchmarks.
Conclusion
Depending on your use case, you might reach for a different tool to benchmark your code:
python -m timeit "some code"for the simplest, easiest-to-run benchmarks where you just want to get "a number".python -m timeit -s "setup code" "some code"is a much more useful version if you want to separate some setup code from the actual benchmarks.docker- while it looked like it did a better job separating my benchmarks from other processes, thus lowering the deviation between runs, after thorough testing, that seemed to be the case for very short examples. For longer ones it didn't really change much.rich-benchlooks like a nice solution if you need a dedicated tool with additional statistics like min, max, median, and nice output formatting. But you will need to set up your benchmarks in a specific structure that rich-bench requires.pyperfgives you the most advanced set of statistics about your code. And it's used by the official Python benchmarks, so it's an excellent tool for advanced benchmarks.hyperfineis a great tool to benchmark any command, not only Python code. Or to compare two different commands.
Ok, technically, I could print the current time with
time.time(), run my code, printtime.time()again, and subtract those two values. But, come on, that's not simple, that's rudimentary. ↩︎


